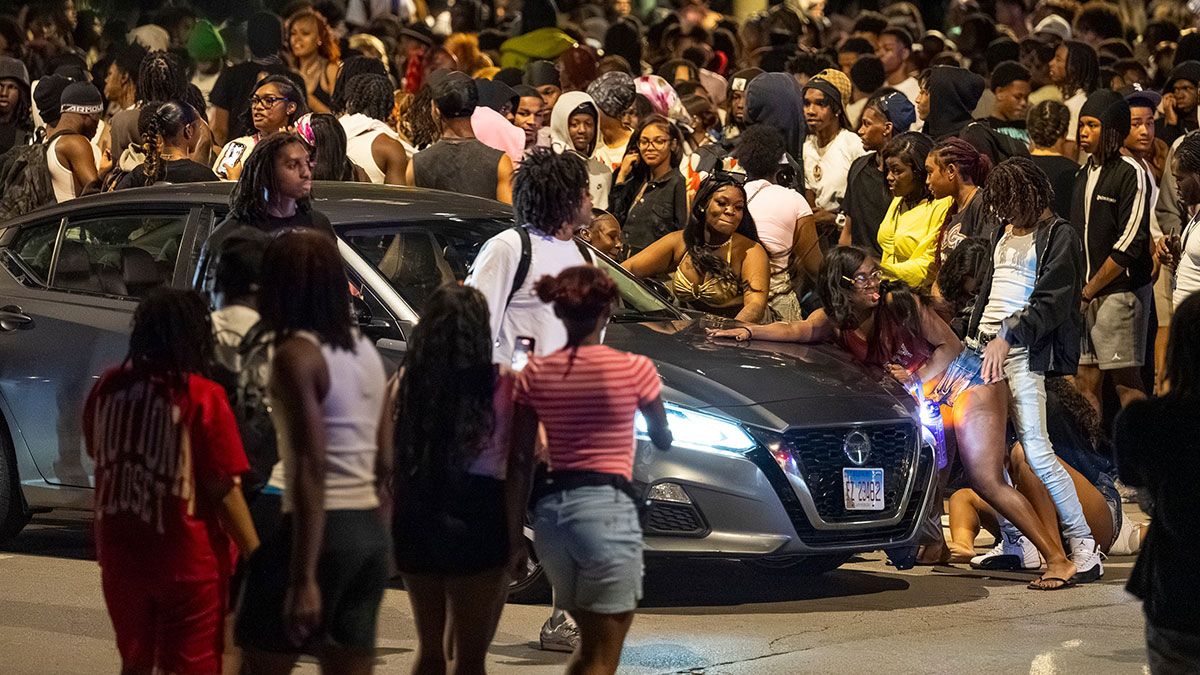This past Memorial Day, more than 1,000 teens swarmed the blocks around Lake Michigan in Chicago’s Hyde Park neighborhood. A resident described the scene: “Hundreds of people were walking and running down our street, jumping on top of cars, twerking, smoking blunts.” One group twerked on the top of a city bus.
At about 9 pm, the Chicago Police Department closed Lake Shore Drive. As sirens wailed, the Hyde Park resident armed himself with bear spray to retrieve something from his car. An hour later, a gunman shot three teens a block from the resident’s home. The suspect remains at large, though police made 13 arrests for illegal gun possession, battery of an officer, and other felonies.
The previous day, an after-prom gathering in Chicago’s Little Italy neighborhood descended into mayhem. “It looked like a million kids out here,” one neighbor told WGN News. “They were acting like straight animals. Kids were all on top of cars. They were stopping in the middle of the street, twerking.” Fights involving pepper spray and other weapons were common. Cars sped through the crowds. Shortly before 3 am, a police commander formed skirmish lines. Three minutes later, a sedan veered into oncoming traffic and struck an officer. Moments afterward, it hit a second officer, crossed into another lane, accelerated, and plowed into three more cops. The rampage ended when the vehicle crashed into a police car and a utility pole. The 18-year-old driver was carrying a semiautomatic handgun with an extended magazine. An hour later, shots were fired in the area, but no arrests have been made.
These two incidents are just a few of the mass-disorder events this year that have been dubbed “teen takeovers.” Nationally, violent felonies overall are down, but disorder is not.
Teen takeovers come in two varieties: pedestrian and vehicular. Pedestrian takeovers feature hordes of youths on foot commandeering roadways, sidewalks, beaches, and malls. Vehicular takeovers, also known as sideshows, involve cars performing daredevil stunts at intersections, on freeways and bridges, and in parking lots. Vehicular sideshows originated in Oakland, California; they are distinct from Chicano lowrider culture. Spectating, inevitably accompanied by filming, is risky: a woman was killed by an out-of-control car in Los Angeles in 2022; this June, a man was fatally shot at a sideshow in a southwest Chicago mall parking lot.
The distinction between pedestrian and car takeovers is not absolute. Pedestrian takeovers attract reckless drivers. And vehicular takeovers sometimes end with participants rushing to the nearest convenience store, stripping the shelves, and assaulting the cashier.
Takeovers are organized on social media, with anonymous flyers summoning mass gatherings. The exact location may remain undisclosed until the last minute. The notices sometimes draw on gangster rap and Black Power imagery, featuring masked men and raised fists. Others are less ominous. A flyer for a teen “trend” (another label for the phenomenon) on a South Shore Chicago beach this spring called for “no drama” and showed a cartoon figure with its naked butt thrust out in twerking stance.
Not all takeovers devolve into violence, but when they do, social media again snaps into play. Dozens of phones are held aloft in the hope of making a viral video. Violence has acquired a performative, specular quality, as though staged for maximum circulation online.
Detroit had its own Memorial Day uprisings this year. At one, a 16-year-old was shot; at another, teens looted a gas station and a Family Dollar store. The previous weekend saw three uncontrolled gatherings in the city, including one where a 14-year-old was shot in the chest outside a Gucci store.
Unruly crowds descended on Arcadia Lake in Edmond, Oklahoma, on May 3. An 18-year-old girl was killed and 22 others injured in a burst of gunfire between rival gangs.
In Clearwater, Florida, a 17-year-old was shot at a beach occupied by hundreds of teens on May 31. Similar mobs descended on parks in Tampa and Orlando on April 25 and May 8. In Orlando, two deputies were injured trying to control the melee.
Washington, D.C.’s Navy Yard neighborhood, a gentrifying district of restaurants and small businesses adjacent to Nationals Park, has experienced a string of teen takeovers this year. On March 14, hundreds of black-clad teens surged through the streets, robbing passersby, fighting, and screaming. Businesses locked down; residents took cover. A 15-year-old fired several rounds, and police recovered two other guns. Additional outbreaks occurred on April 11 and May 16. In the May incident, brawling teens took over a Navy Yard Chipotle, hurling chairs while customers cowered.
Hundreds of masked teens commandeered a stretch of I-77 in Charlotte, North Carolina, on April 26, lighting fires with gasoline and launching rockets.
Hooded teens descended on a shopping mall in a northern suburb of Milwaukee on March 29, throwing punches and fleeing police. Houston’s Willowbrook Mall experienced a similar outbreak on April 25; a roller-skating rink on the city’s outskirts was taken over a week earlier.
Businesses in Rehoboth Beach, Delaware, closed rather than risk injury to employees or damage to property during a takeover on May 19, the fifth such incident there since April. The Delaware State Police, the Department of Natural Resources, and police departments from Dewey Beach, Milford, Lewes, Bethany Beach, and Rehoboth Beach were needed to restore order.
Atlanta police recovered ten guns after gunfire broke out during a chaotic teen takeover in the city’s Beltline corridor on February 28.
Businesses in the Bronx’s Bay Plaza mall were unable to protect themselves during a takeover on February 16, 2026. The plate-glass window of a McDonald’s was shattered. An employee said that he feared for his life. While a Five Below store managed to hold off teens who repeatedly tried to force their way inside, a crate was hurled through the front window of a nearby deli in an attempted break-in.
Novelist Scott Johnston was dining at the Short Pump Town Center outside Richmond, Virginia, on March 14 when hundreds of masked teens in black hoodies rushed past, only abruptly to change direction after receiving phone alerts about a brawl elsewhere in the mall. Johnston and his wife took refuge in a clothing store catering to preppy tastes, figuring it would be a low-priority looting target. The mall shut down soon afterward, following rumors of a shooting. Security is now proprietors’ top concern, according to a local business owner who requested anonymity, saying that he would not touch the subject publicly “with a ten-foot pole.”
Children’s carnivals in Tinley Park, Illinois; Fairfield, Connecticut; Florence Township, New Jersey; and Maple Shade, New Jersey, have been canceled in response to mass disorder this year, as has a Houston rodeo.
This is far from an exhaustive list of the 2026 takeovers. Explanations tend to converge on a single point: the teens themselves are not responsible for their actions.
Mayhem on Independence Day
The July 4 takeover of Balboa Peninsula in Newport Beach, California, drew participants from Texas, Florida, Nevada, and other far-flung states. The travelers undoubtedly concluded that the trip was worth it, given the mayhem they inflicted on the usually low-crime area. Participants plundered a Pavilions supermarket, leaving shattered glass and watermelons strewn across the parking lot, shot mortars at officers, and blockaded roadways. The police shut down local businesses in an effort to restore order.
During Buffalo, New York’s Independence Day takeover, a crowd vandalized an officer’s home after he had tried to break up a fight. The officer’s wife and children were trapped inside. Eleven people were shot, but the police were unable to make many arrests, since takeover participants surrounded them to block their functioning.
Mostly female assailants pummeled a female cop in the head after pushing her to the ground at North Charleston, South Carolina’s Independence Day takeover. She had provoked them by trying to keep the peace. Other officers were assaulted as gunfire broke out around them. Passing cars were targeted by fireworks.
Children and young adults in Pensacola, Florida, engaged in “frightening behavior” throughout Pensacola’s Fourth of July takeover, in the words of the police chief. Seven people were shot, one fatally.
Nine people were hit by gunfire during Raleigh, North Carolina’s Fourth of July takeover. Businesses closed to avoid the violence.
Explanation one: loneliness. The takeovers are “not random violence,” Samuel Abrams, a senior fellow at the American Enterprise Institute, told NBC News in May. “It’s not out-of-control youth. More often than not, it is a desperate need for connection. . . . If you are a teen today, you grew up—or came of age—during Covid, when you were locked down,” Abrams explained. “Your social space is a screen; you are lonely; you are probably a little depressed. . . . You are desperate for human interaction and social contact. And when there’s a chance to gather and be part of something larger, we see teens flock to it.”
Explanation two: Covid. The pandemic created a mental-health crisis among teens, maintains Jasmin Ford, a psychiatric nurse practitioner and clinical instructor at the University of Illinois–Chicago. Young people missed key developmental milestones and now suffer from arrested development and the post-Covid loneliness identified by Abrams.
Explanation three: emotional neediness. “A lot of times when you see kids out here, it’s a cry for help,” a member of a Detroit community violence intervention group, The People’s Action, told WXYZ-TV in May.
Explanation four: poverty. One of the greatest stressors a family can face is being poor, Marilyn Luper-Hildreth, founder of Peace City, an Oklahoma nonprofit, told Oklahoma City’s Journal Record in the wake of the deadly teen takeover at Arcadia Lake. Families need to be free from “worry[ing] about whether or not they’re going to feed their children or if OG&E is going to cut off their lights,” said Luper-Hildreth. A Missouri state senator from St. Louis, Karla May, told the Independent: “If we’re not dealing with [poverty and other] underlying causes of crime, that’s the problem.”
Explanation five: hunger. Peace City’s CEO told the Journal Record that some of the most effective programs for reducing group-related violence connect families to food. People commit retail theft “because they need groceries,” according to the director of research at the Chicago Appleseed Center for Fair Courts.
Explanation six: capitalism. The takeovers are a “symptom of . . . capitalism,” suggested Robyn Vincent, host on a Detroit National Public Radio station. Instead of being “built for kids,” American cities were “built for spending money, they’re built for consumerism.” They were “not necessarily built for free safe spaces where people can commune and convene.”
Chicago Mayor Brandon Johnson, when he was still a Cook County commissioner, blamed corporate profits for the looting that followed the death of George Floyd in 2020. Asked to clarify remarks that appeared to excuse the unrest, Johnson told a local television station: “There’s no way to, to, to embrace that. What I’m saying is you can’t condone the looting that corporations continue to do every single day when they take tax dollars from black, brown, and white folks all over the city of Chicago so they can turn a profit. The fact that Jeff Bezos pays a lesser tax rate than people that are seeking employment—that’s a wicked system. That type of looting has to be disrupted as well. That’s what we’re calling for in this moment.”
Explanation seven: the lack of “safe spaces” for teens. Teens “deserve to have spaces where they’re safe, where they can have fun, and where they can gather,” said a lead organizer with Free DC and the Youth Power & Safety Collective at a Washington, D.C., city council meeting in April. Sometimes the envisioned “safe spaces” possess a utopian element. Two Atlanta teens told city school officials and mayoral aides in March that teenagers needed their own “spaces,” modeled on coworking venues, where they could do homework and host charity events. They were promptly awarded $50,000 to create such teen “third spaces.” AEI fellow Abrams lamented that libraries offer rooms for senior citizens and young children but few dedicated spaces for teens.
Explanation eight: no opportunities. A month before Mayor-elect Johnson took office in May 2023, teens swarmed Chicago’s Loop and downtown lakefront. They broke into and torched cars, vandalized property, and clashed with police. Two minors were shot. Johnson posted that, while he did not condone the violence, it was “not constructive to demonize youth who have otherwise been starved of opportunities in their own communities.”
Explanation nine: too much law enforcement. “We’re building prisons and not schools,” maintained Missouri State Senator Karla May. The takeovers are a product of curfews and chaperone policies, according to the president of the Houston-based National Youth Rights Association. (Chaperone policies require adult accompaniment in malls and at public events.) Such rules create “this feedback loop of teenagers being more isolated from each other because they can’t go out and exist in public without these restrictions being placed on them,” the association’s president, Zane Miller, told the Wall Street Journal in May.

None of these explanations withstands scrutiny. The idea that Covid created a generation of lost youths whose longing for connection drives them into rampages runs up against an inconvenient reality: such mob lawlessness predates the pandemic.
Freaknik was an early antecedent of today’s teen takeovers. It began as a spring-break gathering for black college students in Atlanta; by the mid-1990s, it had become notorious for looting and gunplay. In 1995 alone, Atlanta police logged roughly 2,000 criminal incidents. Businesses shut down, and residents fled town. Billed as a celebration of black sexuality, Freaknik kept the rape unit at Grady Memorial Hospital busy. Ten alleged rape victims were treated over a single weekend in 1995. Male attendees paid women to expose themselves or dance in sexually explicit ways on camera, foreshadowing today’s twerking. When Atlanta’s mayor increased the police presence in 1997, he was accused of racism.
Freaknik had petered out by 1999, under relentless law-enforcement pressure. But less organized forms of urban chaos persisted under various names—wilding, the knock-out game, flash mobs. Spring-break violence itself simply changed venues. In recent years, Miami has struggled with thousands of spring-breakers taking over the South Beach area, shooting one another, stampeding, shoplifting, damaging property, and committing sexual assault—in one case, fatally. The city’s eventual crackdowns were attributed to racism, since predominantly white spring-break gatherings elsewhere in Florida did not draw a comparable police response.
In 2010, about 200 teens robbed pedestrians and smashed their way into stores in central Philadelphia. The following year, a Philadelphia mob attacked diners and transit riders while stripping retail establishments. Washington, D.C., New York, Minneapolis, and Cleveland, among other cities, experienced similar outbreaks of youth mob violence in 2011.
In 2013, hundreds of teens overran Chicago’s subway Red Line and the Magnificent Mile, clubbing passersby. In 2018, there were eight major “large group” incidents—the official euphemism in Chicago for teen riots—mostly on North Michigan Avenue and the nearby lakefront, according to CWBChicago. Police efforts to push teens toward a Red Line stop during one of two Memorial Day incidents that year were lambasted as racist. The iconic Water Tower Place, the first vertical mall in the U.S., was mobbed in 2018, setting off a steady attrition of anchor tenants.
Urban chaos, in other words, required no Covid lockdowns. Moreover, if Covid were the cause of contemporary teen takeovers, one would expect all demographic groups to have been affected similarly. Yet white teens are not running across car roofs en masse or twerking atop police cruisers. Whites were arguably more likely to have been strictly constrained by their parents during the lockdown period, given documented differences in parenting practices. Black attitudes toward lockdowns were often more relaxed, as evidenced by the large house parties that routinely occurred after restrictions were imposed. Yet teen takeovers are overwhelmingly black, though the media avoid mentioning that fact.
Other countries had even more stringent lockdowns, but they have not experienced teen takeovers. The lockdowns ended several years ago. Yet black teens allegedly continue to be deprived of social contact to such an extent that they can find solace only in mob action.
The teen takeovers are not about poverty or hunger. Nearly every participant carries a smartphone, making claims of material deprivation hard to sustain. Nearly all are amply supplied with the necessities of life, including food. Mass looting does not target the dairy or meat aisles of grocery stores. It does not seek blankets or warm socks. Convenience stores are plundered not because the looters are starving but because the stores stay open late and are poorly guarded.
The takeovers are not a reaction to a lack of “teen spaces”—not that cities are under any obligation to provide such spaces. City streets are as available to urban teens as to anyone else. True, the reputation of black juveniles precedes them, and a small but consequential contingent continues to reinforce that reputation. As long as black males, on average, commit crime at disproportionately high rates, the law-abiding of all races will be tempted to cross the street and the police will be on alert when large groups assemble. Of course, not all blacks are criminals; millions fervently support law and order and deserve protection in return. Whites commit heinous crimes and destroy public order. But when black males between the ages of 14 and 17 commit homicide at nearly ten times the rate of white males in the same age cohort, as criminologist James Alan Fox has documented, it is rational to take precautions.
Democratic politicians and activists invoke the need for “safe spaces” to justify new government-funded programs for teens. Whether such spaces produce the desired results remains an open question. On April 4, the Washington, D.C., Department of Parks and Recreation hosted a “Teen Spring Jam” at a recreation center near the Navy Yard district. Violent brawls broke out outside the event. Participants assaulted officers and resisted arrest.
A lachrymose quality pervades the call for “safe spaces.” But the chief threat to the safety of any such space comes from the teens themselves. They are the ones beating up and shooting one another, in between assaults on innocent pedestrians and police.
Lack of “opportunities,” as Chicago Mayor Johnson puts it, does not create teen mobs. If a black teen graduates with a modest GPA, basic literacy and math skills, and no criminal record, colleges will compete for his presence. To be sure, a child raised in a two-parent home in Streeterville enjoys a head start in life compared with a child of an unwed mother on the South Side. But the most important difference between them is not income; it is the presence or absence of a father at home and the persistence or erosion of the marriage norm in their respective backgrounds. People have lived on the lower rungs of the economic ladder for centuries without producing routine outbreaks of festive mob violence.
Law enforcement is the response to violent takeovers, not their trigger.
Police officers, district attorneys, and sheriffs offer a different explanation for the teen takeovers: they are the consequence of a decades-long demonization of the criminal-justice system.
Asked how the Chicago Police Department would have responded to a stampede on the Magnificent Mile before that demonization took hold, a recently retired officer with over 30 years on the force replied: “We would have cleared the streets, arrested those breaking windows, looting stores, and assaulting passersby. We would have used pepper spray, fists, and batons to restore order—all of which we did during the Bulls riots [in 1992], the Democratic National Convention in 1996, NATO, and other localized disturbances that didn’t make the news.”
But then, he says, “the bottom fell out. Officers were cast as the enemy by eight years of Obama.” After the shooting of Michael Brown in Ferguson, Missouri, in 2014, followed by those of Laquan McDonald in Chicago that same year and of Freddie Gray in Baltimore in 2015, “we were cleaning spit off our windshields on a daily basis. We were physically attacked more during those years than at any other point in our careers.” Officers feared being sued for lawful tactics that make for bad optics.
The cops disengaged. “We drove by the dope sellers on the corner, asked no questions of the juveniles who were clearly up to no good, and ignored the cars running stop signs and weaving through traffic.” Better just to do your eight hours and go home.
Another retired Chicago cop recalls asking his commanders in 2010 when mobs were storming downtown: Can we make arrests? He was told: just hold the line and move them around. Even were the officers to engage, the chance that the average detained teen would face serious consequences was already low.
In the 1990s and early 2000s, officers had a protective attitude toward business; they took responsibility for the well-being of shopkeepers and their customers, says a Chicago sergeant still on the job. “It’s different now.”
And then, on May 25, 2020, George Floyd died while restrained by a Minneapolis officer. The country’s elites proclaimed that systemic racism had killed Floyd. Politicians and business leaders rushed to explain the ensuing firebombing of police cars and stations, the attempted murder of police officers, and the destruction of businesses as an understandable, even justifiable, reaction to police oppression.
The post-Floyd race-riot era is largely coterminous with the Covid era: lockdowns began in late March 2020, and the riots erupted at the end of May. That overlap has allowed policing skeptics to attribute the crime spike that began in 2020 to Covid rather than to de-policing and de-prosecution. Those same skeptics now apply the argument to teen takeovers as well.
The rest of the world again provides a useful benchmark. Other countries did not experience a comparable surge in crime beginning in 2020, just as they did not experience a wave of teen takeovers. The United States experienced both because police and prosecutors shied away further from imposing consequences on antisocial behavior.
The juvenile-justice system was similarly emasculated in the twenty-first century, for much the same reason as the adult system: to avoid disparate impact. The Obama administration sued school districts for disparities in school-discipline rates between black students and white students. Suspensions and expulsions plummeted. Rather than being punished, insubordinate pupils were directed to “peace circles” and other forms of restorative justice.
Outside the school bureaucracy, cities and states loosened their already-permissive rules for holding juveniles accountable for crimes. From 2008, when Barack Obama was first elected president, through 2021, the rate at which black male juveniles received final dispositions for violent offenses fell 67 percent, according to the National Center for Juvenile Justice. It is unlikely that this decline in adjudications reflected a 67 percent drop in violent crime among black juveniles, given victimization data and the reports of police officers. Instead, budding criminals were increasingly kept out of the juvenile system altogether, whether their misconduct occurred in schools or on the streets. Those who did enter the system encountered increasingly permissive rules.
California is typical of “reformed” states. Every new law over the last ten years has increased leniency toward juveniles, rather than strengthening public safety, says Gregory R. Albright,a Senior Deputy District Attorney in Riverside County, California. The reforms have made it harder to transfer juvenile murderers and other serious juvenile criminals to adult court. Eleven-year-old offenders cannot even be charged in juvenile court, unless they are accused of murder or a forcible sex crime. Any other crime—attempted murder, manslaughter, robbery—and the eleven-year-old offender stays out of juvenile court entirely, in favor of social services. Prosecutors can be kept in the dark about juveniles of any age who commit misdemeanors. The young criminal may simply be assigned an online theft-awareness class, say, in atonement for his lawbreaking.
The liberalization of juvenile criminal liability continues apace in blue cities and states. In May, Maryland Governor Wes Moore signed the Youth Charging Reform Act, making it harder to transfer young felons to adult court. The president of the Maryland State’s Attorneys’ Association responded by asking Moore: “At what point will you begin to understand the reality that so many of your constituents continue to see day after day—that violent juvenile crime continues to grow out of control?” A week earlier, on May 18, 2026, three girls and one boy, aged 12 to 14, were filmed by admiring peers stomping on, punching, and whipping an 11-year-old girl as she lay unconscious and bleeding on the floor of a Baltimore County home during a house party. Characteristically, the Maryland Department of Juvenile Services wanted to “informally adjust” two of the attackers’ cases, thus exempting them from any involvement with juvenile court, but the department was legally required to relent when one of the arresting officers objected to the planned lack of prosecution.
On the school-discipline front, an elementary school student in Harford County, Maryland, stabbed two teachers during afternoon dismissal on June 16.
Sheriff Michael A. Lewis of Wicomico County, Maryland, says that he is “more discouraged than ever before. Michael Brown, Freddie Gray, George Floyd—they changed everything. We’ve never recovered. There’s a lack of enforcement, a lack of will. Juvenile crime is through the roof.”
Businesses in Baltimore’s historic waterfront neighborhood, Fells Point, warn that the takeovers are driving away customers. “It’s cost us millions, and I’m not kidding when I say millions of dollars, having the roads blocked off,” the owner of a local pub told the Baltimore Sun in late June. “It’s cost us millions of dollars from having the crime that’s been going on, and you know we can’t exist going forward like this.”
Democratic elites have been telegraphing a message to black teens: as victims of white oppression, you are not responsible for your misbehavior. Theft is a reasonable response to a rapacious economic system; violence in the name of racial justice is understandable. The average teen may not follow politics closely, but the sentiment behind Brandon Johnson’s 2025 pronouncement about law enforcement (“It is racist; it is immoral; it is unholy—and it is not the way to drive violence down”) is widespread enough to penetrate even the hermetic world of teen culture.
Juveniles are likelier to resist arrest now, says a Chicago commander. And when young offenders do fight back, officers will think twice before using lawful force to gain compliance, lest the inevitable smartphone video shows up on the news.
Throughout most of the twentieth century, so blatant an insult to police authority as twerking on the top of police cars would not have been tolerated. Now the downside risk of removing a resisting twerker is too great. So the taunting continues unchecked.
Several decades ago, finding a rifle during a downtown flash mob was like finding the Holy Grail, says Chicago officer John Dalcason. Today, youths bring Glocks to takeovers, often equipped with switches that convert them into automatic weapons.
The ideal solution to the teen takeovers is a change in culture—both in the elite culture that excuses lawlessness in the name of racial justice and in urban black culture itself.
It is taboo to acknowledge the racial demographics of the takeover phenomenon—until it becomes time to play the race card and blame whites for overreacting to supposedly imaginary black crime. Laurence Steinberg, an oft-quoted psychology professor at Temple University, mocks the “dog whistling” that occurs when black teens gather in large groups. The suggestion that “we should be afraid of them” is as ludicrous today as it was during the uproar over “wilding” and “super-predators” in the 1980s and 1990s, Steinberg told the New York Times in May.
Kristin Henning, a Georgetown University law professor who specializes in juvenile justice, is also a frequent media source, owing to her claim that white and black juveniles behave similarly but are treated differently. Black and Hispanic youths “are disproportionately stopped, searched and frisked by authorities responding to reports from local residents and business owners who perceive these youth as presumptively violent, criminal and threatening,” she told USA Today. Henning complained to the New York Times that white youths in skate parks during the 1980s and 1990s did not generate the same level of surveillance and arrests as black gatherings do today.
But white children in skate parks were not shooting one another or attacking cops. Police stop and question juveniles in response to reports of crime. A study of four large cities found that black juveniles were 100 times more likely to be shot than white juveniles during what the researchers defined as the “pandemic era” (i.e., the post-Floyd race-riot era). Though the study avoided the question, the victims’ assailants would have been overwhelmingly black themselves, in light of other crime data.
There is almost certainly another racial element to the takeovers: the desire to intimidate whites and show contempt for “white” norms. No less august an authority than Martin Luther King Jr. explained rioting and looting to the American Psychological Association in 1967 as “mainly intended to shock the white community.” King observed: “Often the Negro does not even want what he takes; he wants the experience of taking. But most of all, alienated from society and knowing that this society cherishes property above people, he is shocking it by abusing property rights.” Twerking is a more recent challenge to bourgeois sensibilities, to the extent those sensibilities still exist.
Left-wing academics and activists are probably right that the sight of thousands of black teens swarming public thoroughfares triggers racial panic among whites. But that panic is not irrational. For more than half a century, socialization has failed in large segments of the black population, driven largely by family breakdown. Darious Morris, a member of Detroit’s police oversight board and an unapologetic advocate of personal responsibility, told Detroit public radio in May that up to 95 percent of the youths he mentors in a building-trades program lack fathers at home. The mothers are often disengaged from their children’s upbringing. Parent–teacher nights in Detroit’s public schools are sparsely attended. Yet, Morris observed, lines stretched around the block for the opening of a new beauty-supply store. If parent–teacher nights drew similar crowds, he argued, juvenile crime would look very different.
The latest violent takeover in Detroit occurred on a Sunday night. Why were children even out on a school night? Morris asked. Curfews would not be necessary if parents did their jobs, he said.
Activists raise an outcry over curfews, but the restrictions arouse little concern among many of those directly affected. A Chicago officer who retired in 2019 recalls that when he brought young curfew violators home, the violation was no big deal for most parents. “They had to sign a form, but they did not seem to care. I rarely had the sense that any discipline was pending. If you told them, ‘The streets are dangerous,’ they would just shrug their shoulders.”
Absent a broader cultural shift, conservative jurisdictions are developing additional ways to curb the takeovers through policing and prosecution. Volusia County, Florida, is emblematic. A takeover at the Daytona Beach pier in March resulted in a stampede among its 10,000 participants. The city declared a state of emergency. Volusia County Sheriff Mike Chitwood activated a “Special Event Zone,” which doubled traffic fines and permitted deputies to immediately impound vehicles. When online promoters responded with calls for another pier takeover in April, Chitwood issued cease-and-desist letters and threatened civil lawsuits to cover the hundreds of thousands of dollars in policing costs. The April takeover never materialized.
After the Daytona Beach stampede, Florida Attorney General James Uthmeier posted: “Congrats: you have my attention. This behavior is unacceptable, and I’m having our Statewide Prosecutors develop a plan to investigate and prosecute those who are responsible for these events. Stay tuned. More to come.”
A planned June takeover of the nearby St. Augustine Beach pier was shut down after the St. Augustine Beach Police Department tracked down the promoters, issued cease-and-desist warnings, and stamped “CANCELED” across the viral flyers on social media.
In May, U.S. Attorney for the District of Columbia Jeanine Pirro announced that her office would pursue criminal charges against parents whose failure to supervise their children results in lawbreaking. Other jurisdictions have passed or are considering parental accountability laws. Enforcing those laws requires manpower to make and process arrests, however, and many police departments continue to suffer from post-Floyd attrition and de facto defunding.
Some efforts to crack down on takeovers have already been thwarted by blue-state politicians. After the May 19 takeover in Rehoboth Beach, police charged four Delaware State University students with facilitating a riot. The local NAACP chapter alleged racism, and on May 29 Delaware’s attorney general ordered the charges dropped.
Meanwhile, Democratic cities and states have rolled out summer-safety plans rich in promises of social services and tight-lipped about punishment. Maryland Governor Moore directed the state’s juvenile-justice and public-safety agencies to prioritize “support programs” and “prevention and intervention programs.” Chicago’s Summer Safety Strategy takes “teen voices seriously” and allows “communities to define their own healing,” Deputy Mayor for Community Safety Emmanuel Andre said at a May press conference. On June 17, the Chicago City Council rejected a proposal to require parents to pay a fine or perform community service if they knowingly permit their child to violate the law. Curfews remain hotly contested in blue jurisdictions; some cities allow them only if the authorities create a simultaneous “safe space.”
A natural experiment is being created to test the relative efficacy of government social programs versus law enforcement in curbing crime.

Teen takeovers are not a mystery. They are the predictable result of a culture that increasingly refuses to hold lawbreakers responsible for antisocial behavior, especially if those lawbreakers are black. Every institution that once imposed discipline—the family, the schools, the juvenile-justice system, the police, even public opinion—has been weakened. Despite elite hopes, government programs cannot substitute for the habits of self-control and respect for law that make civil society possible, however. Until those habits are restored, Americans should expect more takeovers and a widening divide between jurisdictions willing to enforce basic norms and those that are not.